
Day 33 of the 60-day challenge. The tracker we open-sourced last week — @webappski/aeo-tracker — reports 33 out of 100 today: 4 of 12 query-engine cells naming TypelessForm. Perplexity 2/3, ChatGPT 1/3, Gemini 1/3, Claude 0/3. Zero paying customers. This article is the 25-day arc that got us there: the manual measurements that first revealed the gap, the Week 1 number that turned out to be measuring the wrong model, and the npm install spike that made the tracker worth building in the first place.
Below is the snapshot I was working from on Day 25 — three queries, four engines, one spreadsheet, ten Chrome tabs. By the time I'd finished it I knew I was going to spend a weekend writing the CLI that made all of this reproducible. The Day 33 baseline at the top of this post is the first run of that CLI on TypelessForm. The two articles read end-to-end as one story: why we built it and the manual data trail that prompted it.
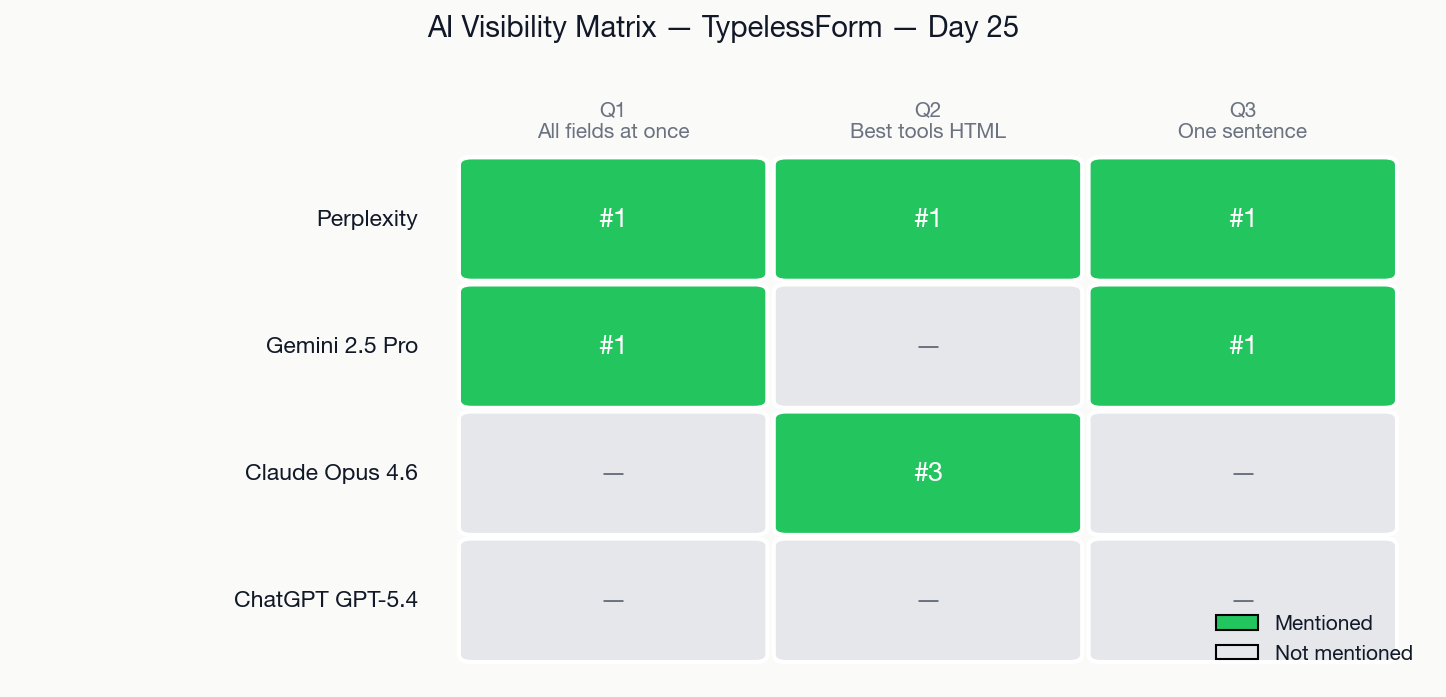
One thing to flag before you read the body: the manual Day 25 numbers below (Perplexity 3/3, Gemini 2/3, Claude 1/3, ChatGPT 0/3 — six positive cells out of twelve) look better than the Day 33 tracker score at the top of this post (4 of 12, 33/100). They are not contradictions, they are different methodologies. Two specific reclassifications happened between Day 25 and Day 33: Perplexity Q1 was a "mentioned in cited source URL only" hit that the tracker classifies as unverified rather than verified; Gemini Q3 was a no-grounding-source response (the model knew us from training data but did not cite live web pages) — the tracker counts that as a hit but applies a stricter verified/unverified split via two-model cross-check. The 33/100 above is the stricter, reproducible weekly number we will track against from now on. Everything below is the manual Day 25 snapshot — kept as-is so the methodology evolution is auditable.
Day 25 Snapshot in Five Numbers
- 3/3 — Perplexity mentions TypelessForm on every benchmark query (stable since Week 1)
- 2/3 — Gemini 2.5 Pro ranks us #1, once without even searching the web
- 0/3 — ChatGPT browser model (GPT-5.4) shows nothing (Week 1 measured a different model)
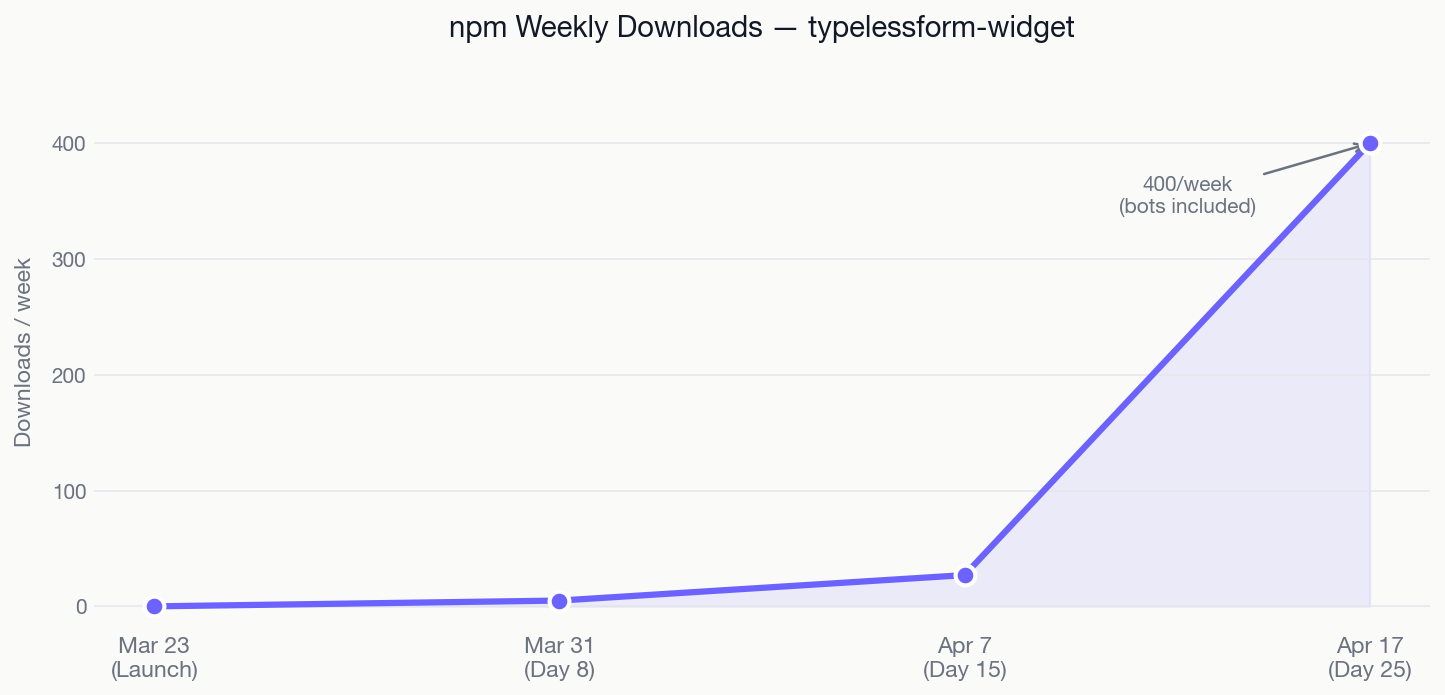
- +1381% — weekly npm installs jumped 27 → 400 between Day 15 and Day 25 (bots included — see caveat below)
- $0 — paying customers. Visibility moves faster than revenue.
What Changed
npm Package Downloads
| Period | Downloads/week | Change |
|---|---|---|
| March 23 (launch) | ~0 | — |
| March 31 (Day 8) | ~5 | baseline |
| April 7 (Day 15) | 27 | +440% |
| April 17 (Day 25) | 400 | +1381% |
TypelessForm ships as an npm package — one npm install command, works with any HTML form. In the last 10 days, the weekly download rate jumped 14×. This is organic: no ads, no Product Hunt launch.
Important caveat: npm numbers include bots, crawlers, and CI pipelines rerunning installs. But a 14× spike in 10 days is not noise. Something got indexed or shared in a developer community I haven't pinpointed yet.
AI Engine Visibility — The Full Picture
What is AEO? AI Engine Optimization is what SEO was in 2005 — measurable, mostly unoptimized, and about to matter. It tracks whether ChatGPT, Perplexity, Gemini, and Claude mention your product when someone asks a relevant question. Unlike SEO, there's no dashboard. You check by asking the engines directly.
In Week 1 I reported: "Top result on Perplexity, top widget on Gemini, #2 on Claude, invisible on ChatGPT." That was accurate. But it was missing nuance I've since learned to measure.
I now test three queries representing how real users discover TypelessForm:
| Query | Intent |
|---|---|
| Q1: "Fill all form fields at once with voice" | Direct feature match |
| Q2: "Best tools voice input HTML forms" | Comparison/discovery |
| Q3: "Voice input fills entire form one sentence" | Natural language feature search |
Perplexity: 3 out of 3
Perplexity mentioned TypelessForm on all three queries:
- Q1 — first product listed: "TypelessForm – widget that adds a microphone button to any form; you speak once and it fills multiple fields at once."
- Q2 — #1 under "Ready-to-use form widgets": "TypelessForm – One-shot voice form-filling widget; drop a <script> tag, users speak once, and AI populates all fields at once. Works with any standard HTML form, supports 25+ languages, and is GDPR-compliant."
- Q3 — first mention, with detail: "TypelessForm – A one-shot voice widget where users say something like 'My name is Anna, email anna@example.com' and the script automatically fills all matching fields in one go."
After each answer, Perplexity generated follow-up questions exclusively about TypelessForm:
"How to integrate TypelessForm into an HTML form"
"TypelessForm pricing and plans"
"TypelessForm vs Web Speech API"
When an AI engine uses your product name as the answer and your product name as the suggested next question — that's what category ownership looks like.
Gemini: 2 out of 3 — and one unusual signal
| Model | Q1 | Q2 | Q3 | Score |
|---|---|---|---|---|
| Gemini 2.5 Pro (current) | ✅ #1 | ❌ | ✅ #1 | 2/3 |
| Gemini 2.0 Flash (previous gen) | ❌ | ✅ ~#4 | ❌ | 1/3 |
On Q3, Gemini 2.5 Pro put TypelessForm #1 — but with no grounding sources. No search citations, no live URLs. The model described TypelessForm accurately ("over 25 languages… AI populates fields, user reviews and edits") from training data alone.
That matters because training data is stable. Search index positions fluctuate daily. When a model knows your product without searching, that mention doesn't disappear when your rankings shift.
Claude: 1 out of 3 — and a flywheel signal
| Model | Q1 | Q2 | Q3 | Score |
|---|---|---|---|---|
| Claude Opus 4.6 (current) | ❌ | ✅ #3 | ❌ | 1/3 |
| Claude Sonnet 4.5 (previous gen) | ❌ | ✅ #3 | ❌ | 1/3 |
Claude found TypelessForm on Q2. What's interesting is the source it cited: our own blog article (/blog/best-ai-form-filling-tools-2026). We published a comparison, Claude indexed it, and now uses our content as the category reference when users ask for the best tools.
We wrote the article. Claude cites it. Readers ask Claude. Claude cites our article again. That's a content flywheel — small now, but compounding.
ChatGPT: 0 out of 3 — and the Week 1 correction
| Model | Q1 | Q2 | Q3 | Score |
|---|---|---|---|---|
| GPT-5.4 (current browser) | ❌ | ❌ | ❌ | 0/3 |
| GPT-4o-search-preview (old model) | ❌ | ✅ #1 | ❌ | 1/3 |
This is where Week 1 needs a correction. In Week 1, I reported a ChatGPT score of 33/100. That measurement used GPT-4o-search-preview — the previous-generation model. The model every ChatGPT user actually opens in a browser today is GPT-5.4. That model shows TypelessForm zero times across all three queries.
On Q2, where the old model ranked us #1, the new model recommends: Web Speech API, OpenAI Realtime API, OpenAI Audio Transcription. The new model defaults to its own ecosystem as the authoritative source.
The Week 1 number wasn't wrong — it was measuring the wrong thing. ChatGPT browser visibility today: 0 out of 3 queries.
Summary vs Week 1
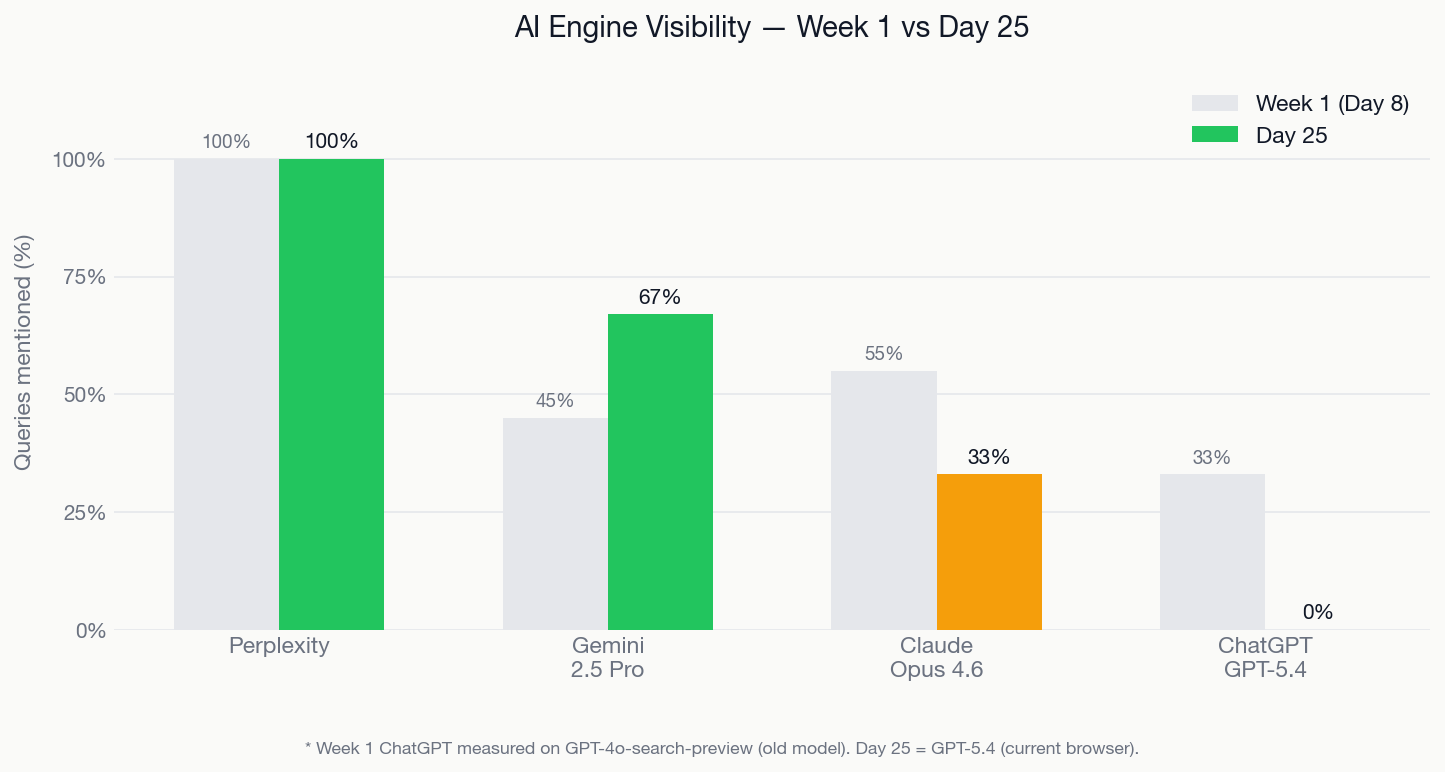
| Engine | Week 1 | Day 25 | Notes |
|---|---|---|---|
| Perplexity | Top result | 3/3 = 100% | Stable, category owner |
| Gemini 2.5 Pro | Top widget | 2/3 = 67% | Improved; answers from training data |
| Claude Opus 4.6 | #2 | 1/3 = 33% | Cites our blog as source |
| ChatGPT GPT-5.4 (browser today) | — | 0/3 = 0% | First clean measurement |
| ChatGPT GPT-4o (old model) | 33/100 | 1/3 = 33% | Week 1 measured this generation |
Google Search Console — Impressions +115%
Google Search Console shows a clear jump: 384 impressions for Apr 5–11 vs 179 for Mar 29 – Apr 4. That's +115% week-over-week. Clicks are still 2 — organic traffic is only beginning to convert.
New queries appearing that weren't there in Week 1: "ai tools for filling complex compliance forms", "automatic web form filling software", "typeless ai". These are new entry points from content published in weeks 2–3.
Bing AI Performance — 4 Citations
Bing Webmaster Tools added an AI Performance section (beta) tracking citations from Microsoft Copilot. Over 3 months: 4 citations, 2 of them appearing in the last week. Bing is citing us and the count is growing. This section didn't exist — or wasn't visible — in Week 1.
Google Search Positions
9 keywords in top 10. Stable across two measurement weeks — no large gains, no losses.
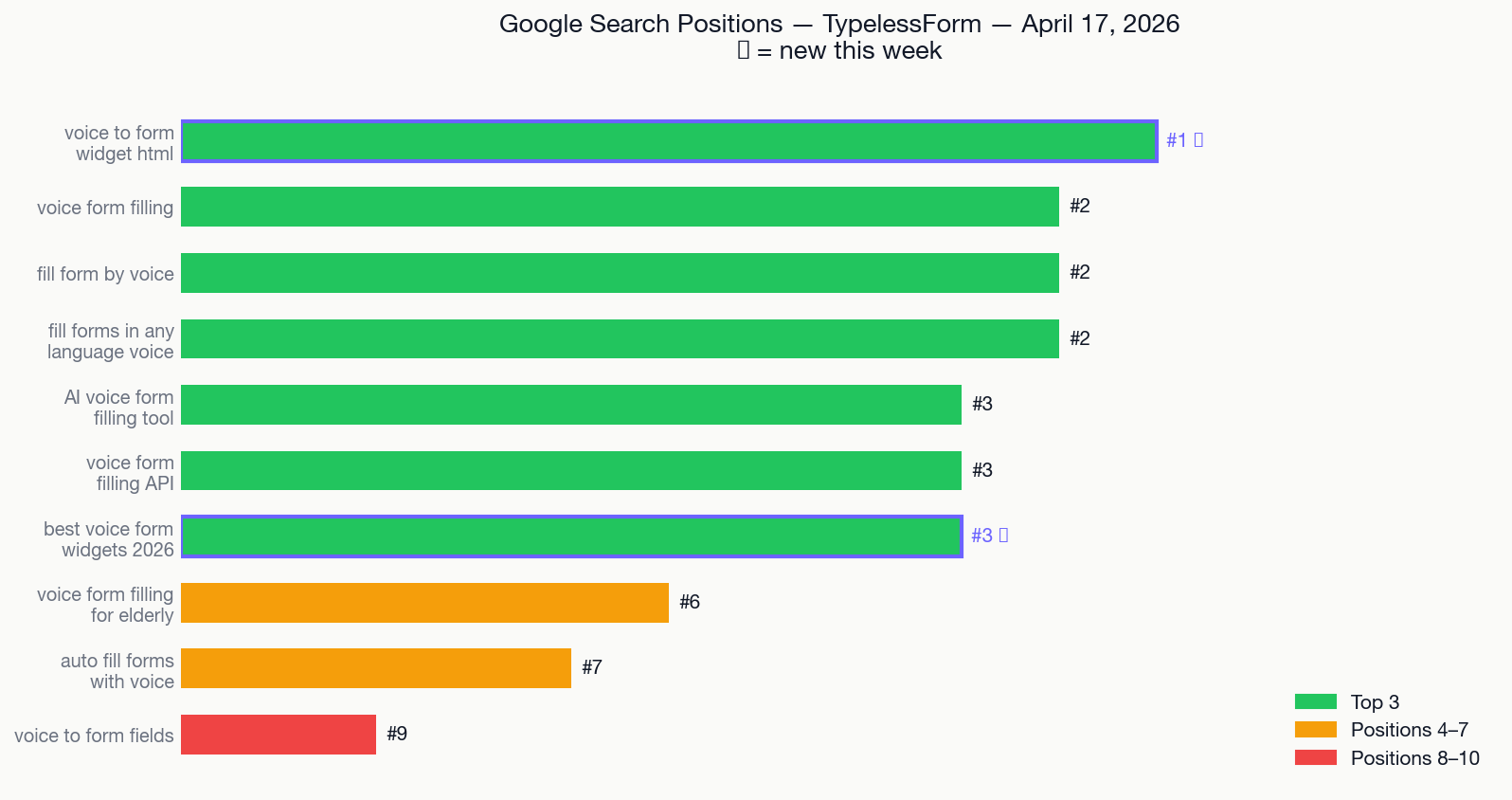
"voice to form widget html" ranking #1 was a discovery, not a campaign. Developers searching for this exact technical phrase land on TypelessForm first.
The main gap: nextux.ai (a single blog post, not a product) holds #1 for six or more core voice queries. A blog article from one developer outranks a working product. That gap is still open as of Day 33 — it carries into Week 5.
The Content Machine — 20 Articles in 25 Days
Since launch, the blog went from 0 to 20+ articles. The ones that generate AI traction share a pattern: a direct answer in the first paragraph, a comparison table, and explicit competitor names. Some of what's live now:
- TypelessForm vs AnveVoice
- TypelessForm vs Web Speech API
- TypelessForm vs Speak2Web
- Voice form filling widget vs form builder
- Best voice form filling widgets 2026
- How to add voice input to HTML forms
Claude now cites one of these articles as a category source. That's the first external AI citation signal — and it came from our own content.
What I Got Wrong in Week 1
1. The ChatGPT score. I measured GPT-4o-search-preview — the previous-generation model. The model ChatGPT users actually see today (GPT-5.4) returns zero for our queries. Week 1 wasn't wrong, it was measuring the wrong thing. Model generations matter. The number that counts is what the current browser shows.
2. "Perplexity — top result." That was accurate in Week 1 and it's confirmed in Week 3: 3 out of 3 benchmark queries, with follow-up suggestions exclusively about TypelessForm.
Three Surprises
After 25 days of tracking, three results I did not predict:
Surprise 1: Gemini answered without searching the web. On Q3 — the query that most precisely describes what TypelessForm does — Gemini 2.5 Pro returned TypelessForm #1 with no grounding sources. No live search. The model knows us from training data. That's a different kind of visibility from a search ranking.
Surprise 2: Claude cited our own article back to users. We published a comparison piece. Claude indexed it. Now when users ask Claude for the best voice form filling tools, it cites that article as the reference. We created the source that an AI engine recommends. Content as citation.
Surprise 3: npm became an organic discovery channel. The package page on npmjs.com/package/typelessform-widget generated more inbound signals than our landing page. Developers find products through package registries. That wasn't in the original distribution plan.
About the Methodology
The "what" on this page — every score, every cell, every competitor name — is public, every week. The "how" used to be private. As of April 23, it isn't anymore: the measurement layer is now an open-source CLI. We Built a Free AEO Tracker Because No Tool Gave Us the Truth — the full write-up, the same 33/100 score broken down cell by cell, and the npm package you can run on your own brand for ~$0.20 per weekly run.
What stays with Webappski is the part the CLI doesn't do: reading the matrix on Monday morning, deciding which gaps are worth filling, pitching the canonical sources, writing the comparison pages. Measurement is commodity. Interpretation and execution aren't. That's a conversation.
Platform Update
| Platform | Day 1 | Day 8 (Week 1) | Day 25 | Δ since W1 |
|---|---|---|---|---|
| npm installs/week (bots incl.) | ~0 | ~5 | 400 | +1381% |
| Google impressions/week | ~0 | ~179 | 384 | +115% |
| Blog articles | 0 | 0 | 20+ | +20 |
| Google keywords top-10 | 0 | — | 9 | first tracked |
| Bing Copilot citations | 0 | 0 | 4 | +4 |
| Perplexity visibility | — | Top result | 3/3 | confirmed |
| LinkedIn connections | 314 | 333 | ~350 | +17 |
| Paying customers | 0 | 0 | 0 | = |
The last row is the most honest one. Twenty articles, 9 top-10 keywords, Perplexity on every benchmark query, 400 weekly npm installs — and zero paying customers. That gap between visibility and revenue is the challenge of Weeks 5 and 6.
What's Next
Week 5 priorities (writing this on Day 33): restart cold outreach (hotels, insurance SaaS, booking platforms — the verticals went quiet in weeks 2–4 while content and the tracker build were the focus), write one article targeting Q3 exactly, and close the ChatGPT gap through developer-oriented content that references the authoritative sources GPT-5.4 already cites.
The Honest Frame
Thirty-three days, zero revenue, and AI engines that cite my own blog back to my readers.
That's the 2026 distribution game: you can be #1 on Perplexity, ranked by Gemini without web search, and cited by Claude as the category source — and still need to pick up the phone and call hotels in Week 5.
Visibility compounds. Revenue doesn't — until you ask for it.
If you're building something and want to know how AI search engines see your product — reach out. We track this for ourselves every week. It's become one of the most useful signals we have.